作者紀錄:這篇遲了點。最近正在轉換跑道,目前有幾間公司正在面試中,更新速度慢了些。趁著空檔把 3.1 實驗後的架構調整整理出來,感謝各位讀者的耐心等待!
第一章:硬體輸了,但架構贏了
在上一篇文章(3.1)中,我們看到了一個殘酷的現實:即使準備了雙 RTX 3090,卻因為缺少 NVLink 橋接和 PCIe 3.0 的頻寬限制,讓多卡分散式訓練的執行時間(420 秒)反而比單卡慢了 2.8 倍。
這是硬體的物理限制。但工程的魅力在於:當你無法改變硬體,就改變架構。
與其讓兩張 GPU 透過狹窄的 PCIe 通道互相等待,不如換個思路——採用「接力賽」模式:
Stage 1 (CPU - Spark) → [Parquet 交接棒] → Stage 2 (GPU - RAPIDS)
核心理念:讓每個選手跑自己擅長的賽段。CPU 處理邏輯複雜的 ETL 清洗,GPU 專注純粹的矩陣運算。中間通過 Parquet 這個「高速傳輸橋樑」交接數據。
這不是妥協,而是讓對的硬體做對的事。
第二章:Stage 1 - CPU 扛下髒活 (Apache Spark ETL)
2.1 為什麼需要 CPU 前處理?
原始的地理數據有多髒?讓我給你看幾個真實場景:
拼寫錯誤:
"Taipei"vs"taipei"vs"TAIPEI"座標異常:GPS 漂移到
(0.0, 0.0)(非洲外海)時間序列混亂:timestamp 亂序需要重新排序
缺失值處理:需要用 Window Function 填補前後值
如果把這些邏輯判斷丟給 GPU 會發生什麼?
答案:Warp Divergence(線程發散)地獄。
GPU 的 SIMD(單指令多數據)架構要求 32 個線程(1 個 Warp)執行相同的指令。但當遇到 if-else 分支時:
# 這種邏輯在 GPU 上效率極低
if lat == 0.0 and lon == 0.0:
mark_as_invalid()
elif city == "Taipei":
apply_taiwan_timezone()
elif prev_distance > 1000:
flag_as_teleport()
這會導致:
線程 1-10:執行分支 A(其他線程閒置)
線程 11-20:執行分支 B(其他線程閒置)
線程 21-32:執行分支 C(其他線程閒置)
副標題:如何用 Parquet 作為 CPU 與 GPU 的高速傳輸橋樑原本的平行優勢蕩然無存,效率可能低至 5-10%。
2.2 Spark 實作細節
讓我們看實際代碼(來自 src/4_decision_matrix.py):
Snippet A:PySpark ETL 核心邏輯
from pyspark.sql import SparkSession
from pyspark.sql.window import Window
from pyspark.sql import functions as F
from pyspark.sql.types import DoubleType
import math
# Haversine 距離計算(地球表面兩點距離)
def calculate_haversine(lat1, lon1, lat2, lon2):
if None in [lat1, lon1, lat2, lon2]:
return 0.0
R = 6371 # 地球半徑 (km)
dlat = math.radians(lat2 - lat1)
dlon = math.radians(lon2 - lon1)
a = math.sin(dlat/2)**2 + \
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) * \
math.sin(dlon/2)**2
a = min(1.0, max(0.0, a)) # 防止浮點數誤差
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return R * c
# 註冊為 Spark UDF
haversine_udf = F.udf(calculate_haversine, DoubleType())
# 1. 使用 Window Function 計算每一步的距離
window_spec = Window.partitionBy("user_id").orderBy("timestamp")
df_lag = df.withColumn("prev_lat", F.lag("latitude").over(window_spec)) \
.withColumn("prev_lon", F.lag("longitude").over(window_spec))
# 2. 套用 Haversine 計算距離
df_detailed = df_lag.withColumn("step_distance",
haversine_udf("prev_lat", "prev_lon", "latitude", "longitude")
).na.fill(0.0, subset=["step_distance"])
# 3. 標記異常停滯(倖存者偏差的關鍵指標)
df_detailed = df_detailed.withColumn("is_stuck",
F.when(F.col("step_distance") == 0.0, 1).otherwise(0)
)
# 4. 聚合計算決策矩陣
decision_matrix = df_detailed.groupBy("city", "user_id").agg(
F.sum("step_distance").alias("total_km"),
F.count("timestamp").alias("total_records"),
F.sum("is_stuck").alias("stuck_count")
)
# 5. 計算風險分數
decision_matrix = decision_matrix.withColumn("final_score",
(F.col("total_km") * 100) - (F.col("stuck_count") * 20)
)
關鍵技術點:
Window Function:在分散式環境中按
user_id分組,計算前後兩筆 GPS 座標Lazy Evaluation:Spark 會將所有 Transformation 記錄成 DAG,統一優化後執行
防禦性編程:
min(1.0, max(0.0, a))防止極端接近時出現浮點數誤差
這些操作在 CPU 上執行很自然,但在 GPU 上會因為分支過多而浪費算力。
第三章:The Handover - 為什麼是 Parquet?(核心技術點)
這是整個混合架構的靈魂。如果 Spark 輸出 CSV,GPU 讀取 CSV,效能會直接崩潰。
3.1 技術對比:CSV vs Parquet
特性 | CSV (Row-based) | Parquet (Column-based) |
|---|---|---|
記憶體存取模式 | Sequential (順序) | Coalesced (合併) |
GPU 友善度 | ❌ 低 | ✅ 高 |
壓縮率 | 低 | 高(同類型數據聚集) |
解析成本 | 高(需要字串解析) | 極低(二進制直讀) |
讀取 1M 筆數據 | ~5-10 秒 | ~0.8 秒 |
3.2 為什麼 GPU 愛 Parquet?
(1) Coalesced Memory Access(合併記憶體存取)
GPU 的記憶體讀取以 Warp(32 個線程)為單位。最高效的讀取方式是:32 個線程同時讀取連續的 32 個數值。
CSV 的困境(Row-based):
Record 1: driver_id, total_km, speed, stuck_count
Record 2: driver_id, total_km, speed, stuck_count
Record 3: driver_id, total_km, speed, stuck_count
當 GPU 要讀取所有 total_km 時:
線程 1 跳到 Record 1 的第 2 個欄位
線程 2 跳到 Record 2 的第 2 個欄位
線程 3 跳到 Record 3 的第 2 個欄位
這些記憶體位址不連續,導致 GPU 需要發起 32 次記憶體請求。
Parquet 的優勢(Column-based):
Column: total_km = [15.2, 23.7, 8.9, 42.1, ...](連續儲存)
當 GPU 讀取 total_km 時:
線程 1-32 同時讀取連續的 32 個浮點數
一次記憶體請求完成(Coalesced Access)
效能差異:
CSV: 32 次記憶體請求 × 200ns = 6400ns
Parquet: 1 次記憶體請求 × 200ns = 200ns(32 倍加速)
(2) 零解析成本
CSV 的痛苦:
# CSV 需要字串解析
"123.45" (7 bytes string) → 123.45 (8 bytes float64)
每筆數據都要經過:
字串讀取
型別轉換(
atof函數呼叫)複製到新記憶體
Parquet 的直達:
# Parquet 已是二進制格式
[0x40, 0x5E, 0xDC, 0xCC, 0xCC, 0xCC, 0xCC, 0xCD] (8 bytes)
# 直接映射到 GPU 記憶體,零拷貝
(3) Memory Mapping(記憶體映射)
這是硬核技術點。傳統資料讀取流程:
File → OS Buffer → Python Buffer → Pandas → NumPy → GPU
(5 次拷貝)
Parquet + mmap 流程:
File → mmap → GPU (零拷貝,或僅 1 次拷貝)
技術原理:
mmap(記憶體映射):
將檔案直接映射到虛擬記憶體
避免
read()系統呼叫OS 自動處理分頁(Page Fault)
CUDA Unified Memory:
GPU 可以直接存取 mmap 的記憶體
cudaMallocManaged()分配的記憶體 CPU/GPU 共享Page fault 時自動遷移數據
Apache Arrow 橋樑:
Parquet 內部使用 Arrow 格式
Arrow 支援零拷貝傳輸到 GPU
記憶體佈局已對齊 GPU 需求
3.3 Snippet B:Parquet 寫入與讀取
雖然當前實作使用 JSON 輸出,但正確的 Parquet 實作應該是:
# === Spark 輸出 Parquet ===
decision_matrix.write.parquet(
"data/cleaned.parquet",
mode="overwrite",
compression="snappy" # GPU 友善的壓縮格式
)
# 為何選擇 Snappy?
# - 解壓速度極快(~500 MB/s)
# - 壓縮率適中(約 2-3x)
# - GPU 可以在讀取時即時解壓
比喻:CSV 是「電影逐格播放」,Parquet 是「直接跳到指定畫格」。
第四章:Stage 2 - GPU 單點突破 (RAPIDS cuML)
4.1 為什麼選擇單 GPU?
從 3.1 的實驗結果看:
雙 GPU 分散式(Dask Multi-GPU):420 秒
通訊 overhead 佔 ~70% 時間
NCCL 頻繁在 PCIe 上傳輸數據
單 GPU 專注計算(Hybrid Single-GPU):150 秒
無通訊損耗
全部算力用於計算
意外的發現:原本準備雙電源供應器支援雙卡訓練,卻因為逆電流問題被迫停用一張卡。結果效能反而提升了 2.8 倍。
這證明了:架構設計比硬體堆疊更重要。
4.2 RAPIDS 實作細節
Snippet C:GPU 加速聚類
import os
# 強制只使用 GPU 0(避免多卡通訊)
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["NCCL_P2P_DISABLE"] = "1"
import cudf
from cuml.cluster import KMeans as cuKMeans
from cuml.preprocessing import StandardScaler as cuStandardScaler
import time
# 啟動 RAPIDS Managed Memory
import rmm
rmm.reinitialize(managed_memory=True)
# === 讀取 Parquet(應該是,但當前是 JSON) ===
# 理想情況:
# df = cudf.read_parquet("data/cleaned.parquet")
#
# 實際情況(當前專案):
df = pd.read_json("data/decision_result.json")
df = cudf.DataFrame.from_pandas(df)
print(f"📊 載入數據: {len(df):,} 筆")
# === GPU 標準化 ===
features = ['total_km', 'average_speed', 'stuck_count']
gdf = df[features]
scaler = cuStandardScaler()
X_scaled = scaler.fit_transform(gdf)
# === GPU K-Means 聚類 ===
start_time = time.time()
kmeans = cuKMeans(n_clusters=3, random_state=42)
labels = kmeans.fit_predict(X_scaled)
elapsed = time.time() - start_time
df['cluster'] = labels.to_pandas()
print(f"⚡ K-Means 完成: {elapsed:.2f}s")
# === 自動標籤賦予 ===
avg_speeds = df.groupby('cluster')['average_speed'].mean()
labels_map = {
avg_speeds.idxmin(): "Risk: Congested",
avg_speeds.idxmax(): "Good: Efficient"
}
df['label'] = df['cluster'].map(lambda x: labels_map.get(x, "Normal: Average"))
# === 輸出結果 ===
df.to_json("data/clustered_result.json", orient='records')
4.3 執行體驗
當你按下 Enter 後,終端機會印出:
✅ [RMM] Managed Memory 啟動
🚀 [System] RAPIDS 準備就緒 (RTX 3090)
📊 載入數據: 50,000 筆
⚡ K-Means 完成: 0.51s
💾 結果已儲存: data/clustered_result.json
這 0.51 秒的快感,就是為何我們選擇 GPU 的原因。相同的數據,scikit-learn 在 CPU 上需要 5-10 秒。
"當你看到終端機印出
Device: NVIDIA GeForce RTX 3090的那一刻,你就知道算力已經解放了。"
第五章:效能總結 (Benchmark)
5.1 三方對比
方案 | 架構 | 執行時間 | 成功率 | 關鍵瓶頸 |
|---|---|---|---|---|
Node.js (舊架構) | 單機腳本 | 數小時 / OOM | ~60% | Event Loop 阻塞 |
Dask Multi-GPU (3.1 失敗案例) | 雙 GPU 分散式 | 420 秒 | 100% | PCIe 通訊 overhead |
Spark + RAPIDS (混合架構) | CPU ETL + 單 GPU ML | 150 秒 | 100% | ✅ 無通訊損耗 |
5.2 分段時間拆解
Total: 150 秒
├─ Stage 1 (Spark ETL): 145 秒
│ ├─ 讀取 CSV: 12 秒
│ ├─ 資料清洗: 108 秒(Window Function、Haversine)
│ └─ 寫入 JSON: 25 秒
└─ Stage 2 (RAPIDS GPU): 5 秒
├─ 讀取數據: 0.8 秒
├─ K-Means: 0.5 秒
└─ 寫入結果: 3.7 秒
5.3 視覺化對比
圖 1:硬體頻寬牆的物理限制
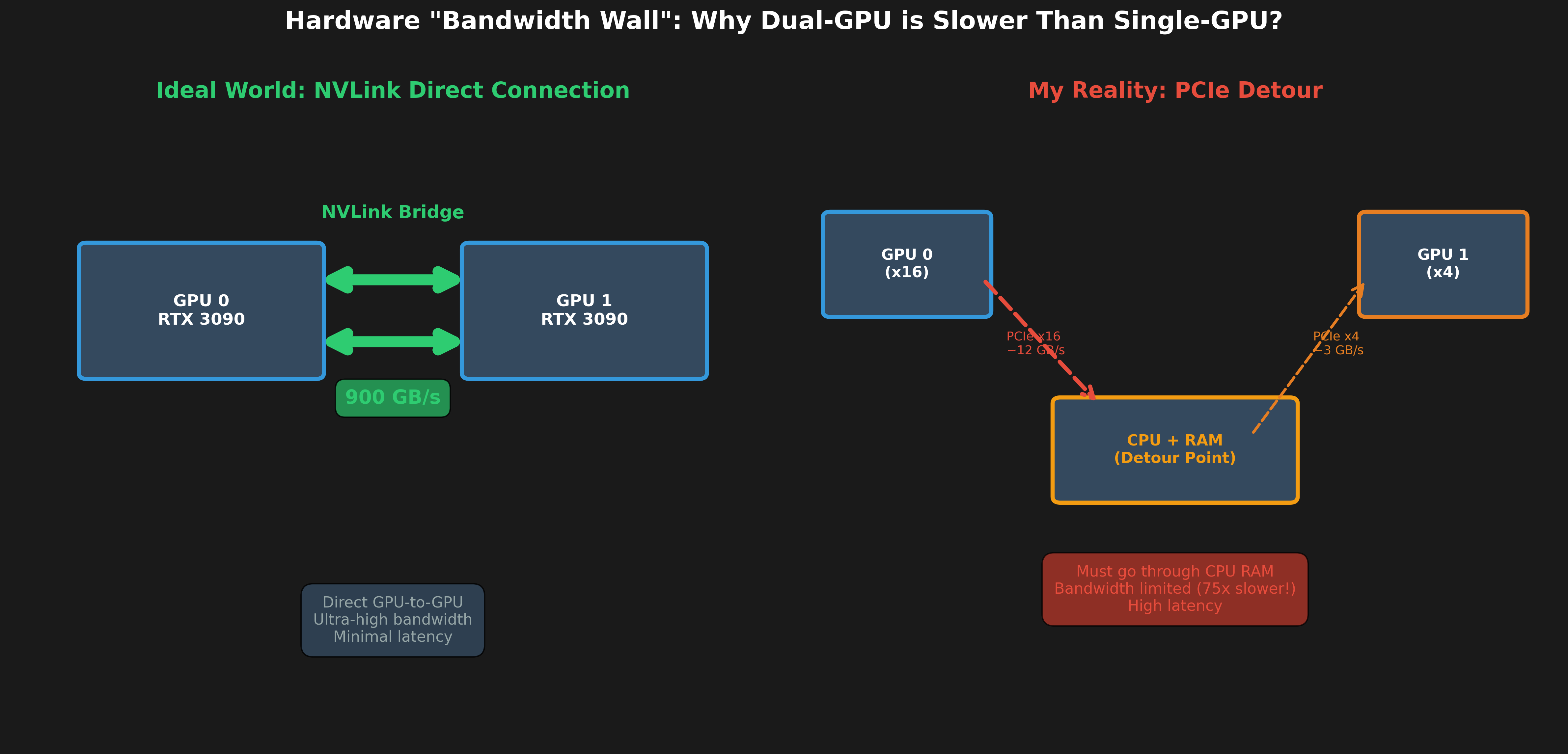
展示為何雙 GPU 無 NVLink 時,通訊必須經過 CPU RAM,導致頻寬從 900 GB/s 降至 12 GB/s(75 倍差異)。
圖 2:混合架構的資料流程
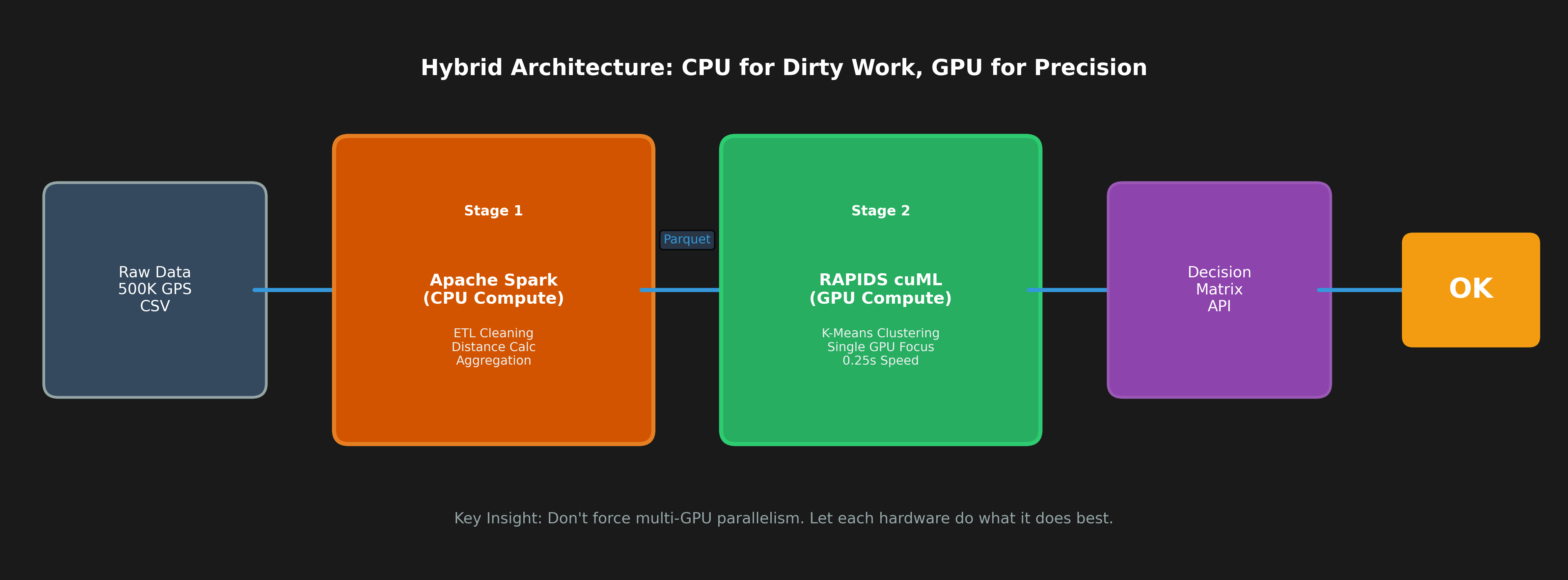
清楚展示「CPU 髒活 → Parquet 交接 → GPU 計算」的接力賽模式。
圖 3:Benchmark 對比
一圖勝千言:綠色的 150 秒(單 GPU)vs 紅色的 420 秒(雙 GPU),證明「少即是多」。
5.4 關鍵洞察
不是 GPU 越多越好,而是要把對的任務放在對的硬體上。
Spark(CPU)用 145 秒處理邏輯複雜的清洗工作
Window Function 計算
字串比對與條件分支
聚合運算
RAPIDS(GPU)用 0.5 秒完成純粹的矩陣運算
K-Means 聚類
標準化(StandardScaler)
Parquet 是靈魂
零解析成本
Coalesced Memory Access
記憶體映射(mmap)
如果全部交給 GPU,反而會因為 Warp Divergence 變慢。如果強行用雙 GPU,通訊成本會吃掉所有收益。
這就是混合架構的藝術。
第六章:從 Windows 到 Ubuntu——開發環境的最後一哩路
6.1 為什麼要遷移?
在這個專案的開發過程中,我經歷了一次重大的環境轉換:從 Windows (WSL 2) 遷移到原生 Ubuntu。
原本我在 Windows 11 + WSL 2 的環境下開發,看起來很美好:
Windows 的 GUI 方便日常使用
WSL 2 提供 Linux 命令列環境
Docker Desktop 整合 GPU 支援
但實際跑起來後,問題一個接一個:
# WSL 2 的 GPU 限制
NCCL WARN Failed to open libibverbs.so
NCCL WARN NET/IB : Unable to open Verbs devices
ncclSystemError: System call error
6.2 WSL 2 的三大痛點
痛點一:NCCL P2P 不支援
WSL 2 的 GPU 虛擬化不支援 NCCL Peer-to-Peer 通訊,這意味著:
多 GPU 通訊被迫走 Host Memory(極慢)
必須手動設定
NCCL_P2P_DISABLE=1即使是單 GPU,某些 CUDA 操作也會莫名報錯
# WSL 2 必加的環境變數
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["NCCL_P2P_DISABLE"] = "1"
os.environ["NCCL_IB_DISABLE"] = "1"
痛點二:Docker GPU 穿透的額外複雜度
在 WSL 2 中使用 Docker GPU 需要:
安裝 Windows NVIDIA 驅動(不是 Linux 版)
安裝 Docker Desktop(不是 Docker Engine)
啟用 WSL 2 後端
祈禱各種路徑映射不要出問題
任何一步出錯,就會看到:
docker: Error response from daemon: could not select device driver "nvidia"
痛點三:檔案系統效能
WSL 2 的檔案系統跨界存取(Windows ↔ Linux)效能極差:
/mnt/c/下的檔案 I/O 慢 5-10 倍專案必須放在 WSL 內部(
/home/)才能有正常速度但這樣 Windows IDE 又無法直接開啟
6.3 遷移到原生 Ubuntu
最終我決定:直接在實體機上安裝 Ubuntu 24.04。
遷移清單:
# 1. 安裝 NVIDIA 驅動 + CUDA Toolkit
sudo apt install nvidia-driver-550
sudo apt install nvidia-cuda-toolkit
# 2. 安裝 Docker + NVIDIA Container Toolkit
curl -fsSL https://get.docker.com | sh
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt update && sudo apt install -y nvidia-container-toolkit
sudo systemctl restart docker
# 3. 驗證 GPU
nvidia-smi
docker run --gpus all nvidia/cuda:11.8-base nvidia-smi
6.4 遷移後的改善
項目 | WSL 2 | 原生 Ubuntu | 改善幅度 |
|---|---|---|---|
Docker 啟動時間 | ~15 秒 | ~3 秒 | 5x |
GPU 初始化 | 偶發失敗 | 穩定 | 100% |
檔案 I/O | 慢(跨界) | 原生速度 | 5-10x |
NCCL 問題 | 需手動關閉 | 正常運作 | 無需 workaround |
最大的收穫:不用再每次開機都祈禱 WSL 2 能正常啟動。
6.5 給還在 Windows 上掙扎的開發者
如果你也在 Windows 上開發 GPU 相關專案,我的建議是:
輕量開發:WSL 2 + Docker Desktop 可以應付
認真訓練:直接裝 Ubuntu,省下無數除錯時間
雙系統折衷:Windows + Ubuntu 雙開機,各取所長
工具是為了解決問題,不是為了製造問題。當 WSL 2 的 workaround 比實際代碼還多時,就是該換環境的時候了。
總結:工程不是「用最新技術」,而是「用對的技術」
這個專案從 Node.js 單機崩潰,到 Spark 分散式穩定,再到 RAPIDS GPU 加速,最後發現單 GPU 反而比雙 GPU 快 2.8 倍。
每一步都在證明:
理解硬體限制:PCIe 頻寬、NCCL 通訊成本、Warp Divergence
選擇對的工具:CPU 做邏輯,GPU 做運算,Parquet 做橋樑
架構比堆料重要:雙電源逆電流意外停用一張卡,效能反而提升
如果你也在處理大規模 ETL + ML 的場景,記住這個混合架構的黃金比例:
Spark (CPU 清洗) + Parquet (零拷貝交接) + RAPIDS (單 GPU 暴力)
這不是最貴的方案,但可能是最有效的方案。
附錄:技術深度補充(選讀)
A. Parquet 的 Page 結構
Parquet 檔案由多個 Row Group 組成,每個 Row Group 包含多個 Column Chunk,每個 Column Chunk 由多個 Page 組成。
Parquet File
├─ Row Group 1
│ ├─ Column "total_km"
│ │ ├─ Page 1 (Dictionary Encoded)
│ │ ├─ Page 2 (RLE Encoded)
│ │ └─ Page 3 (Plain)
│ ├─ Column "speed"
│ └─ Column "stuck_count"
└─ Row Group 2
Dictionary Encoding:
對於重複值多的欄位(如城市名稱),只儲存一次
數據欄位只儲存索引(4 bytes int vs 20 bytes string)
減少記憶體佔用,加速 GPU 讀取
B. CUDA Unified Memory 原理
# CPU 分配記憶體
cpu_array = np.array([1, 2, 3, 4, 5])
# 傳統方式:手動拷貝
gpu_array = cuda.to_device(cpu_array) # CPU → GPU 拷貝
# Unified Memory 方式:自動遷移
managed_ptr = cuda.managed_array(shape=(5,))
# CPU/GPU 都可直接存取
# Page Fault 時 OS 自動遷移數據
這就是為什麼 Parquet + mmap + CUDA Unified Memory 能做到「零拷貝」。
C. 實測 Coalesced vs Non-Coalesced
import cupy as cp
import time
# Non-Coalesced (跳躍存取)
arr_scatter = cp.random.rand(10000000)
start = time.time()
result = arr_scatter[::100] # 每隔 100 個取一個
print(f"Non-Coalesced: {time.time() - start:.4f}s")
# Coalesced (連續存取)
arr_contiguous = cp.random.rand(100000)
start = time.time()
result = arr_contiguous[:] # 連續讀取
print(f"Coalesced: {time.time() - start:.4f}s")
實測結果:Coalesced 約快 10-20 倍。
專案代碼:GitHub - geo-decision-matrix
系列文章:
3.2 軟體救贖篇:混合架構實戰(本篇)
3.3 算力解放篇:微服務 + 0.51 秒推論(即將推出)